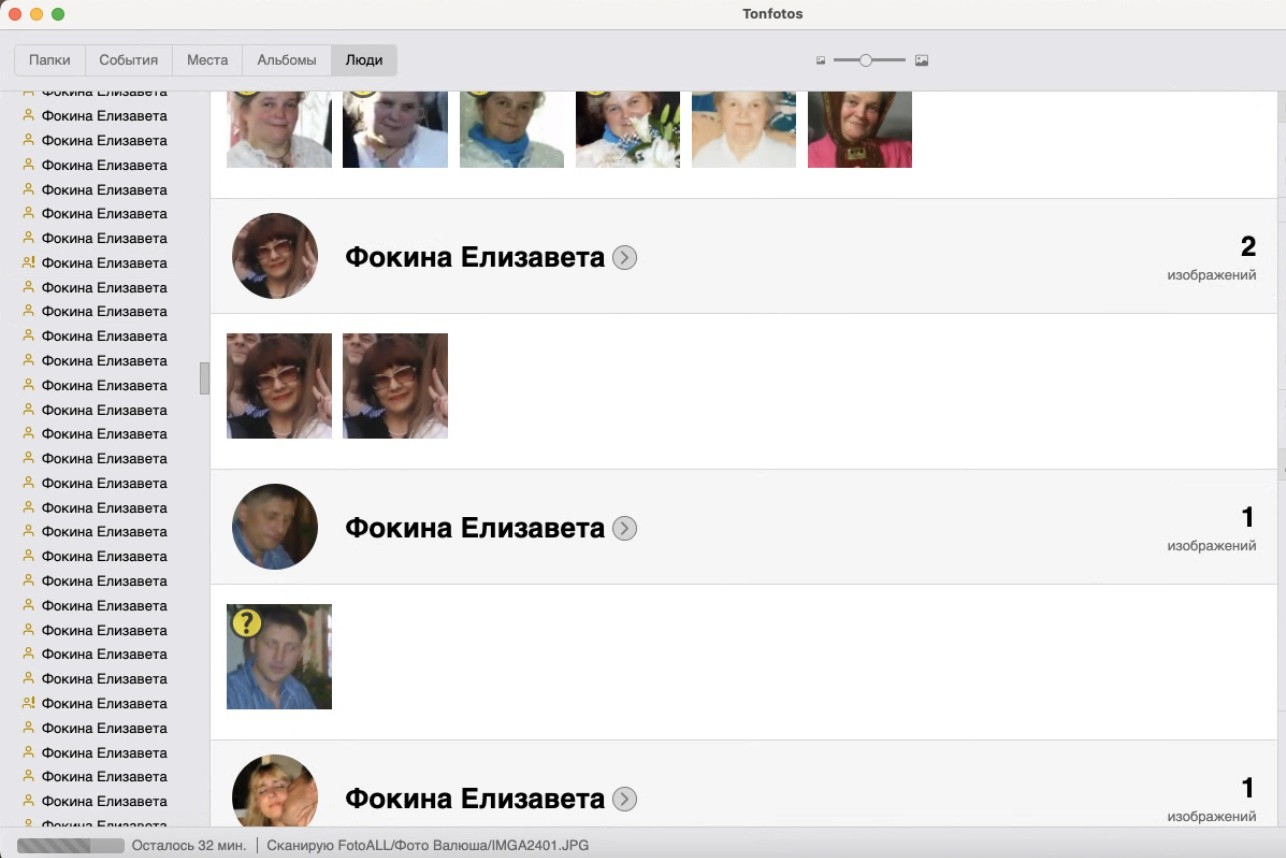
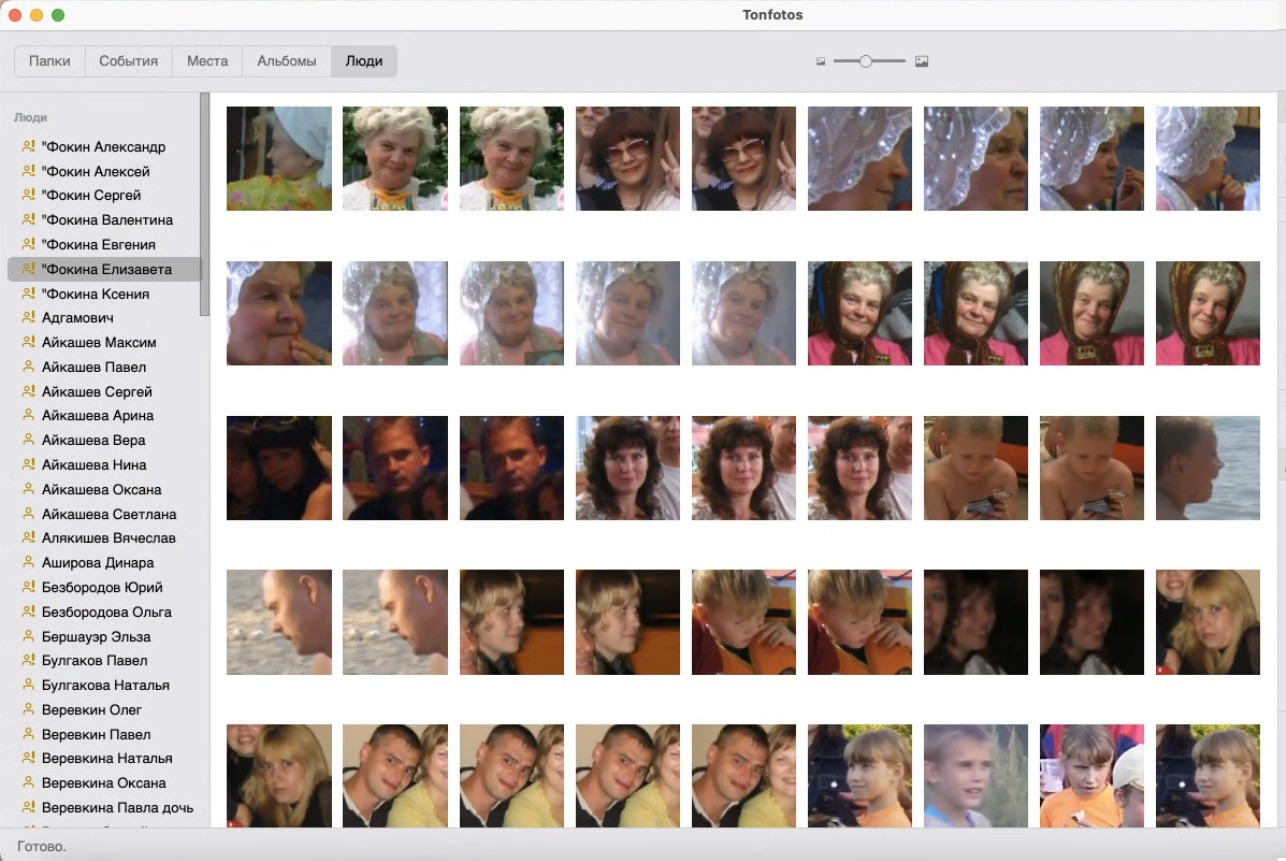
FoksSerg вот тут частично ответил на вопрос “как устроено”. В целом верно представляете процесс, только терминологию не очень верную используете 🙂 За сопоставление лиц и людей отвечает кластеризация, и она ничего заново не распознает, а работает на основе параметров (эмбеддингов) вычесленных на первом этапе при сканировании.
Логика работы кластеризатора довольно простая. Берем все лица, подтверждённые пользователем, и делим их на две группы - те, которые принадлежат текущей персоне, и те, что принадлежат другим персонам. Обучаем на них классификатор. Потом этот же классификатор применяем ко всем лицам, которые пользователь пока никуда не присвоил, и выбираем из них те, которые наиболее похожи на этого человека (наибольшая уверенность классификатора). Если уверенность выше определенного порога - добавляем даже не спрашивая пользователя (но так в жизни очень редко должно быть). Если ниже верхнего порога - то предлагаем на подтверждение, но не больше определенного количества за раз. Если уверенности ниже нижнего порога - то даже не предлагаем.
И так до повторяем по кругу для каждой персоны, пока есть новая информация от пользователя (новые подтвержденные лица).
Мне кажется, что в теории, программу можно свести с ума, выдав ей на вход персоны, в которые добавлены куча совсем разных лиц. И тогда кластер будет очень широким, и даже непохожие лица туда будут залетать как уверенные. Но если аккуратно добавлять лица, то такого быть не должно, мне кажется.