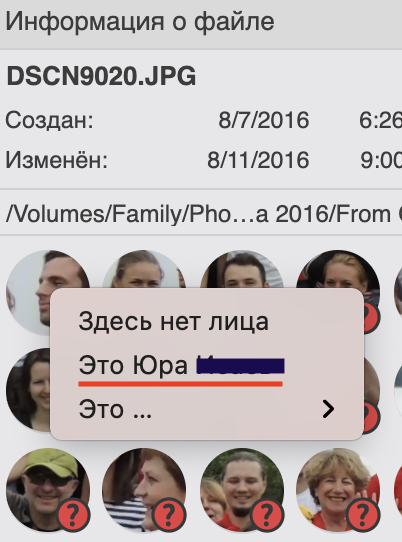
Андрей возможно, я не до конца понимаю механизм работы программы.
В моем понимании, сначала распознается лицо, потом оно подается на кластеризацию, и на выходе получается таблица вероятностей принадлежности этого лица к имеющимся кластерам.
То есть для конкретного обведенного лица у вас внутри есть табличка:
40% - это Маша,
30% - это Миша,
10% - это Коля,
1% - …
…
Дальше берется наиболее вероятное значение (Маша) и, если вероятность выше некоторой пороговой, предлагается пользователю подтвердить, что это Маша, опровергнуть, или выбрать вручную.
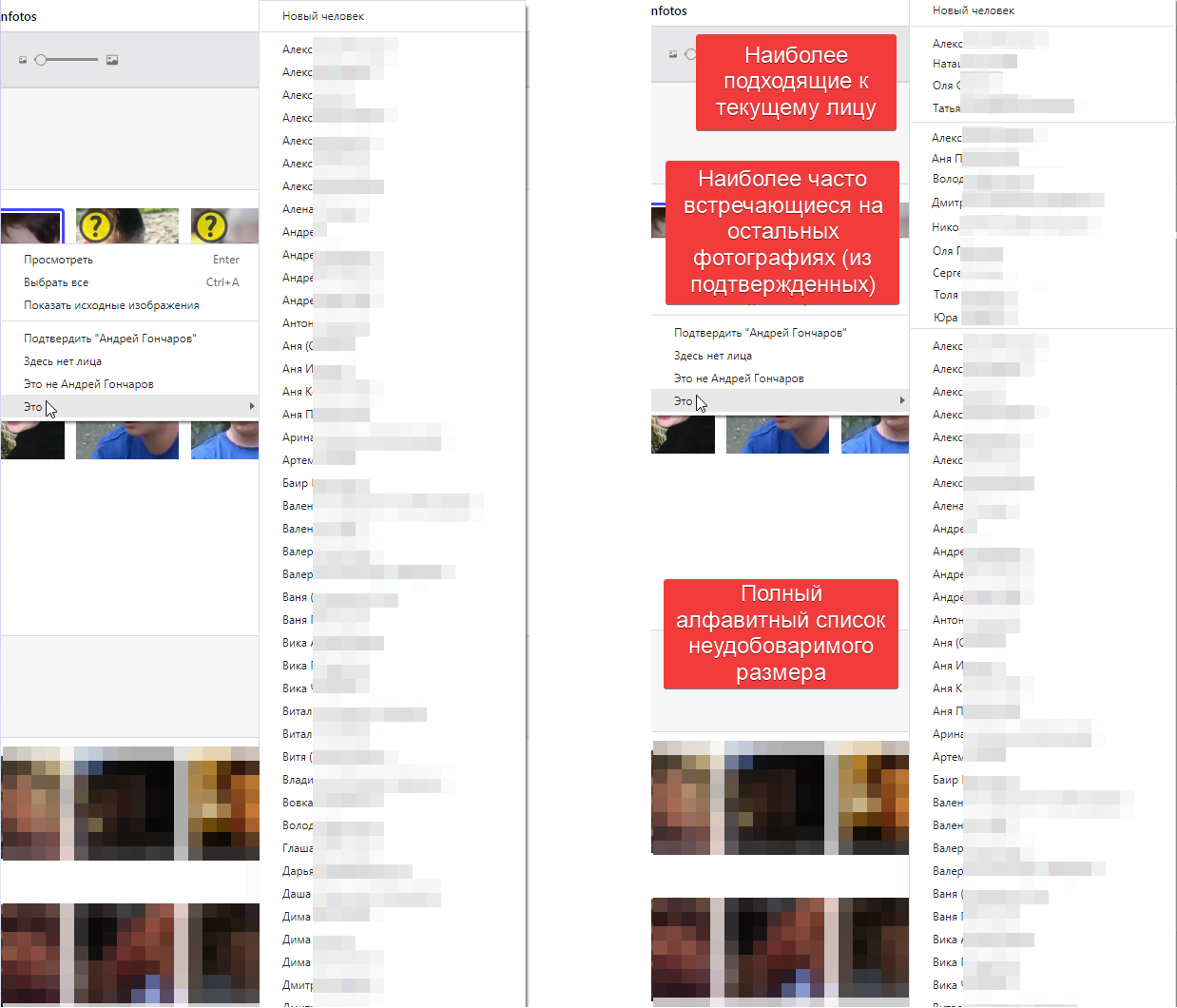
Но выбрать вручную предлагается из всего списка, отсортированного по алфавиту (пункт меню по правой кнопке “Это…”). А можно сверху выделить список остальных наиболее вероятных совпадений - в данном примере Мишу и Колю. Потому что если просто нажать “это не Маша”, то эта картинка сначала пойдет к Мише, потом к Коле и так далее - это долго и неудобно, проще сразу выбрать из небольшого списка. Сейчас список большой и неудобный, поэтому из него выбирать слишком сложно.